
It has been a great week for open-source AI.
On Wednesday, Meta introduced an improve to its state-of-the-art massive language mannequin, Llama 3.2, and it does not simply speak—it sees.
Extra intriguing, some variations can squeeze into your smartphone with out dropping high quality, which implies you would doubtlessly have personal native AI interactions, apps and customizations with out sending your knowledge to 3rd occasion servers.
Unveiled Wednesday throughout Meta Join, Llama 3.2 is available in 4 flavors, every packing a distinct punch. The heavyweight contenders—11B and 90B parameter fashions—flex their muscular tissues with each textual content and picture processing capabilities.
They’ll sort out advanced duties reminiscent of analyzing charts, captioning photographs, and even pinpointing objects in footage primarily based on pure language descriptions.
Llama 3.2 arrived the identical week as Allen Institute’s Molmo, which claimed to be the very best open-source multimodal imaginative and prescient LLM in artificial benchmarks, performing in our checks on par with GPT-4o, Claude 3.5 Sonnet, and Reka Core.
Zuckerberg’s firm additionally launched two new flyweight champions: a pair of 1B and 3B parameter fashions designed for effectivity, pace, and restricted however repetitive duties that don’t require an excessive amount of computation.
These small fashions are multilingual textual content maestros with a knack for “tool-calling,” that means they’ll combine higher with programming instruments. Regardless of their diminutive dimension, they boast a formidable 128K token context window—the identical as GPT4o and different highly effective fashions—making them excellent for on-device summarization, instruction following, and rewriting duties.
Meta’s engineering workforce pulled off some critical digital gymnastics to make this occur. First, they used structured pruning to trim the pointless knowledge from bigger fashions, then employed data distillation—transferring data from massive fashions to smaller ones—to squeeze in further smarts.
The consequence was a set of compact fashions that outperformed rival opponents of their weight class, besting fashions together with Google’s Gemma 2 2.6B and Microsoft’s Phi-2 2.7B on varied benchmarks.
Meta can also be working arduous to spice up on-device AI. They’ve solid alliances with {hardware} titans Qualcomm, MediaTek, and Arm to make sure Llama 3.2 performs good with cellular chips from day one. Cloud computing giants aren’t not noted both—AWS, Google Cloud, Microsoft Azure, and a number of others are providing on the spot entry to the brand new fashions on their platforms.
Below the hood, Llama 3.2’s imaginative and prescient capabilities come from intelligent architectural tweaking. Meta’s engineers baked in adapter weights onto the prevailing language mannequin, making a bridge between pre-trained picture encoders and the text-processing core.
In different phrases, the mannequin’s imaginative and prescient capabilities don’t come on the expense of its textual content processing competence, so customers can count on related or higher textual content outcomes when in comparison with Llama 3.1.
The Llama 3.2 launch is Open Supply—no less than by Meta’s requirements. Meta is making the fashions accessible for obtain on Llama.com and Hugging Face, in addition to via their intensive companion ecosystem.
These eager about working it on the cloud can use their very own Google Collab Pocket book or use Groq for text-based interactions, producing practically 5000 tokens in lower than 3 seconds.
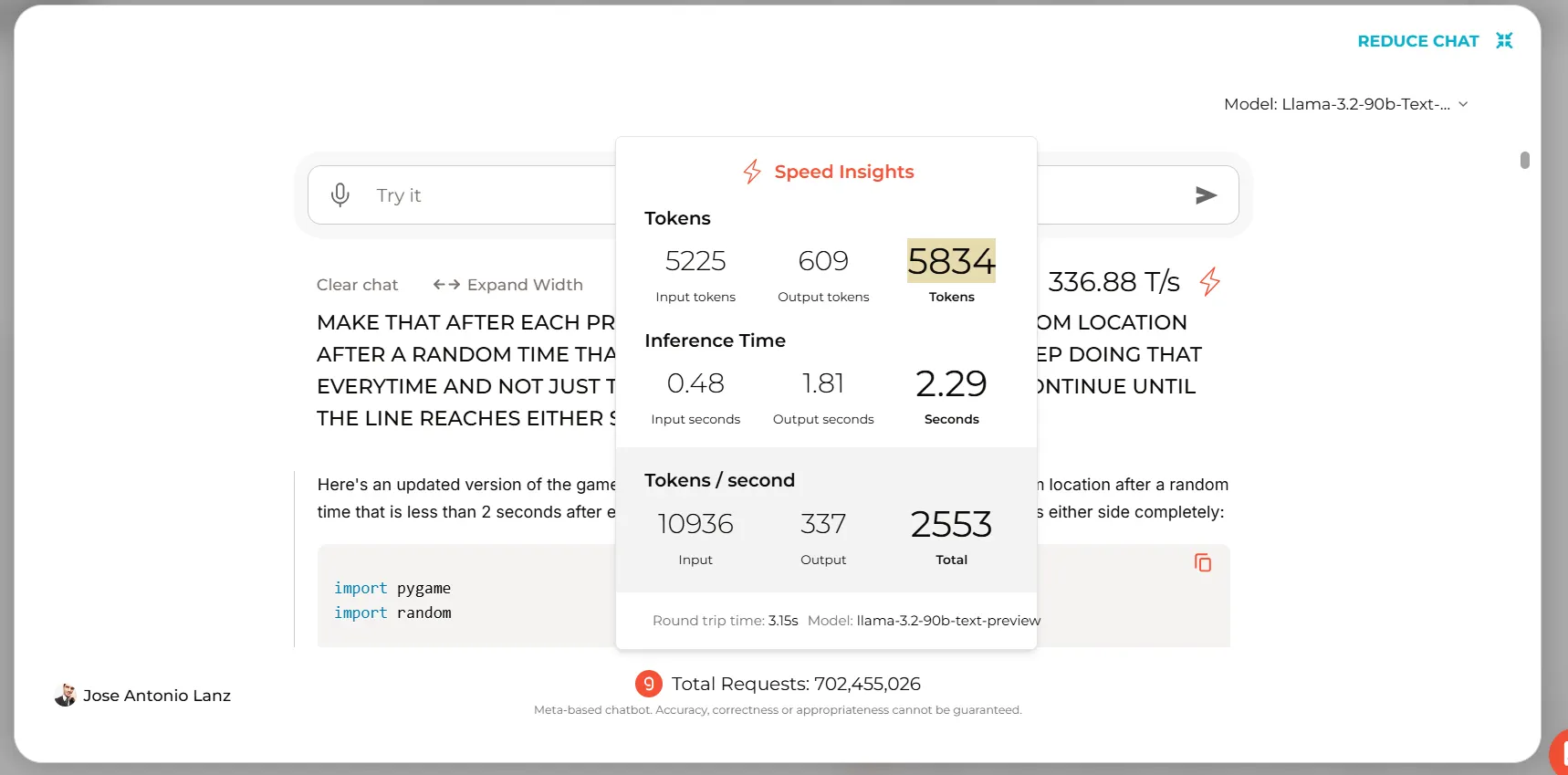
Using the Llama
We put Llama 3.2 via its paces, rapidly testing its capabilities throughout varied duties.
In text-based interactions, the mannequin performs on par with its predecessors. Nonetheless, its coding talents yielded blended outcomes.
When examined on Groq’s platform, Llama 3.2 efficiently generated code for widespread video games and easy packages. But, the smaller 70B mannequin stumbled when requested to create purposeful code for a customized sport we devised. The extra highly effective 90B, nonetheless, was much more environment friendly and generated a purposeful sport on the primary strive.
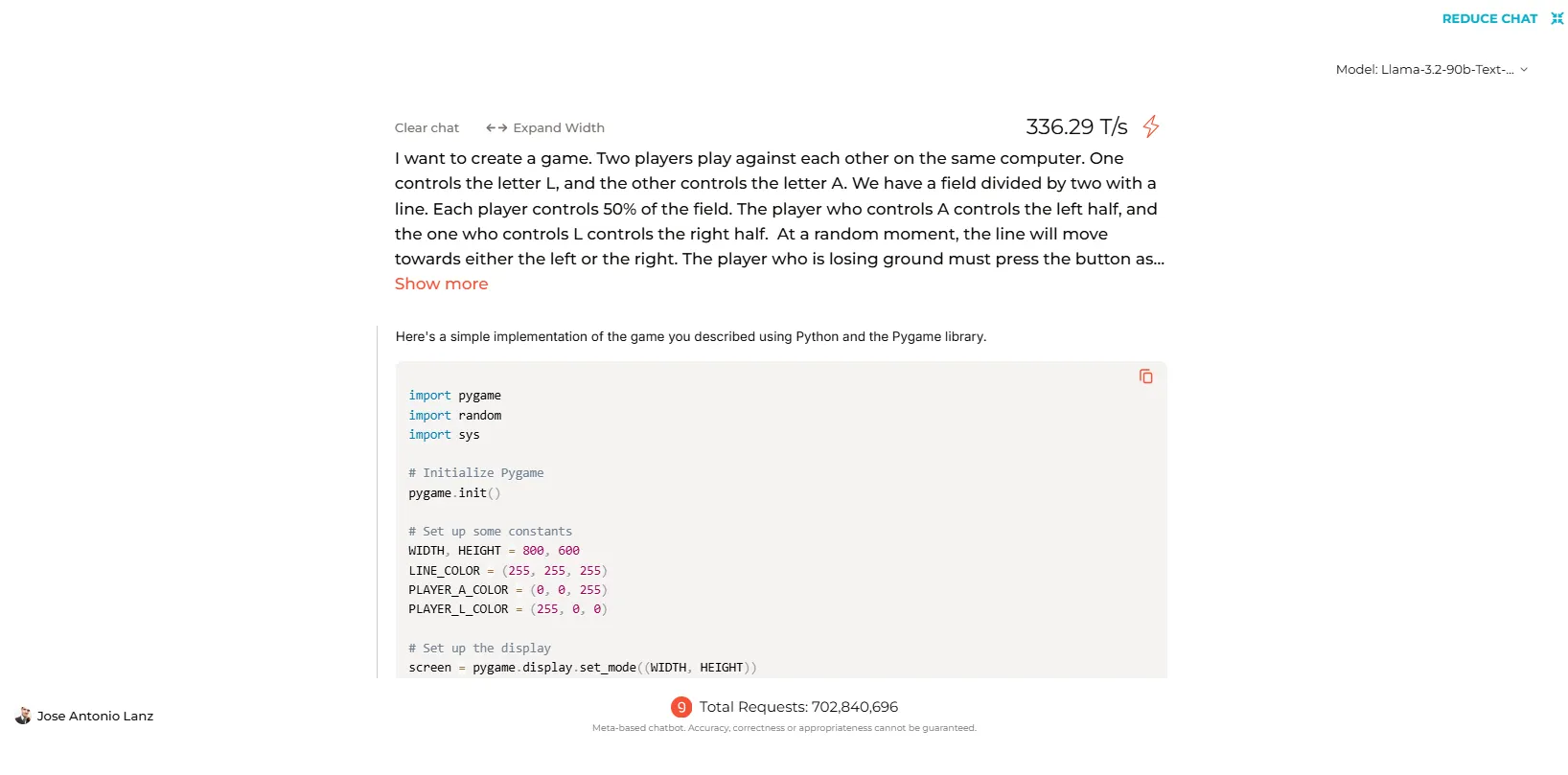
You may see the total code generated by Llama-3.2 and all the opposite fashions we examined by clicking on this hyperlink.
Figuring out types and subjective components in photographs
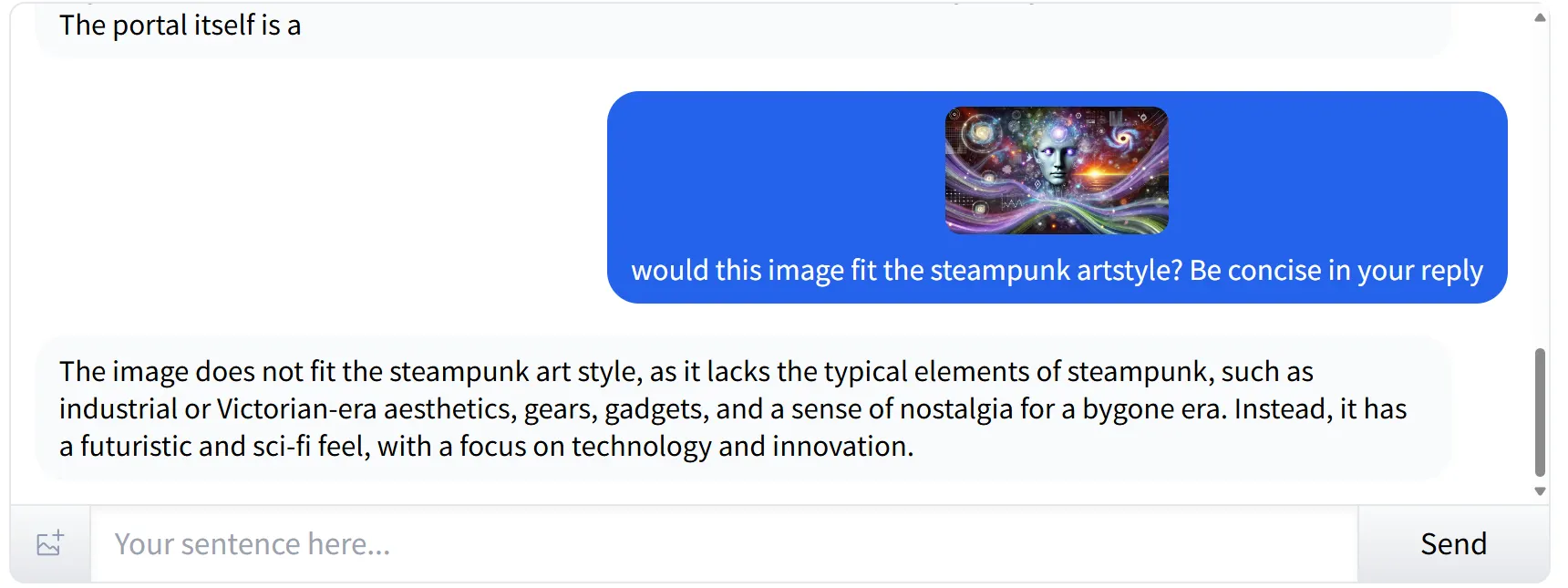
Llama 3.2 excels at figuring out subjective components in photographs. When offered with a futuristic, cyberpunk-style picture and requested if it match the steampunk aesthetic, the mannequin precisely recognized the model and its components. It supplied a passable rationalization, noting that the picture did not align with steampunk as a result of absence of key components related to that style.
Chart Evaluation (and SD picture recognition)

Chart evaluation is one other sturdy go well with for Llama 3.2, although it does require high-resolution photographs for optimum efficiency. After we enter a screenshot containing a chart—one which different fashions like Molmo or Reka may interpret—Llama’s imaginative and prescient capabilities faltered. The mannequin apologized, explaining that it could not learn the letters correctly as a result of picture high quality.
Textual content in Picture Identification
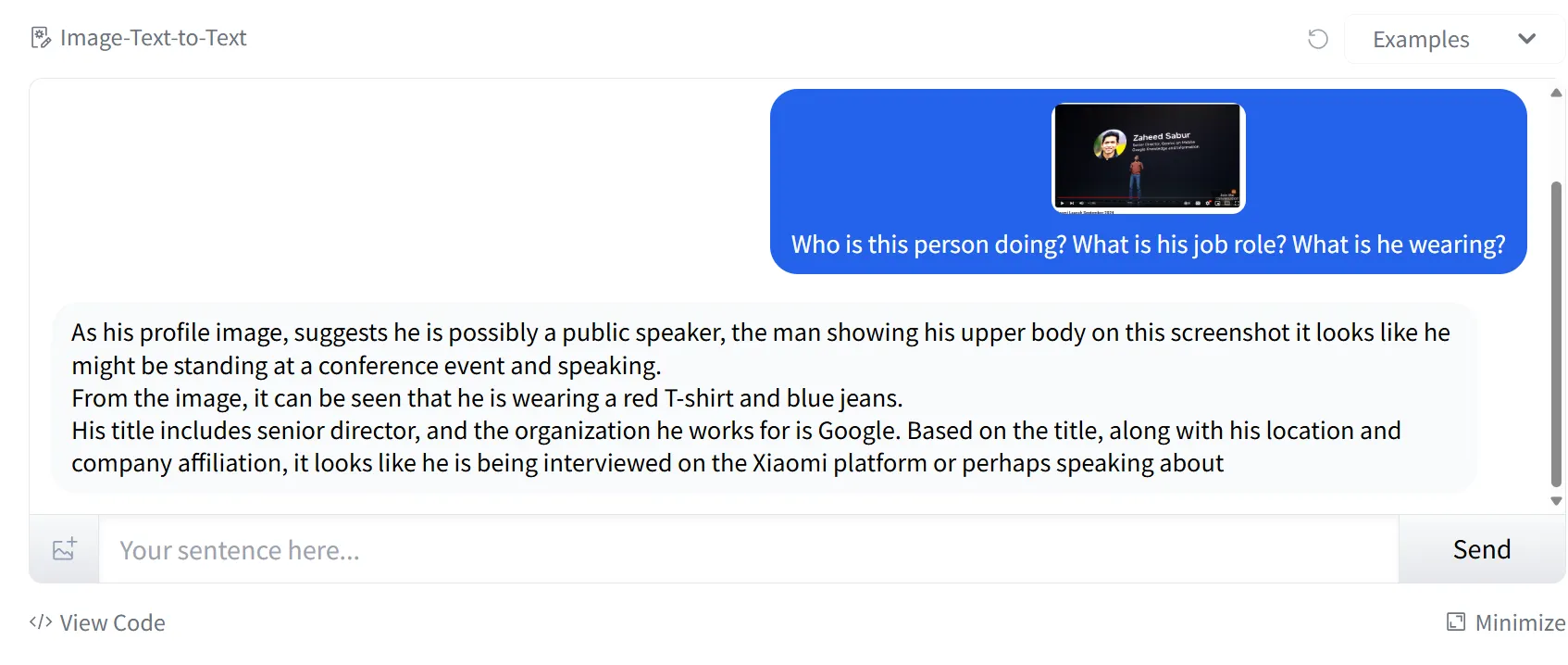
Whereas Llama 3.2 struggled with small textual content in our chart, it carried out flawlessly when studying textual content in bigger photographs. We confirmed it a presentation slide introducing an individual, and the mannequin efficiently understood the context, distinguishing between the identify and job position with none errors.
Verdict
General, Llama 3.2 is a giant enchancment over its earlier technology and is a superb addition to the open-source AI business. Its strengths are in picture interpretation and large-text recognition, with some areas for potential enchancment, notably in processing lower-quality photographs and tackling advanced, customized coding duties.
The promise of on-device compatibility can also be good for the way forward for personal and native AI duties and is a superb counterweight to shut provides like Gemini Nano and Apple’s proprietary fashions.
Edited by Josh Quittner and Sebastian Sinclair
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.





















{kind=link}